Day02(05/30) Hadoop核心技术
查看笔记合集
一、Hadoop伪分布式集群配置及功能测试
0.Hadoop运行环境配置
先进入hadoop文件夹进行配置 cd /home/software/hadoop-2.7.6/etc/hadoop/
(1).vim mapred-site.xml
ps: 前一步要复制一份.xml文件 cp mapred-site.xml.template mapred-site.xml
1
2
3
4
5
6
7
| <configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
|
(2).vim yarn-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
| <configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>qianfeng01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
|
(3).vim slaves
(4).vim /etc/profile 配置Hadoop环境变量
1
2
3
4
| export JAVA_HOME=/home/software/jdk1.8
export HADOOP_HOME=/home/software/hadoop-2.7.6
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export JAVA_HOME PATH
|
(5).source /etc/profile # 刷新环境变量
hadoop version # 查看Hadoop版本号
可以正确看到Hadoop版本说明,环境变量配置正确。

(5).hadoop namenode -format 格式化namenode
运行内容中出现以下这行,说明格式化成功。
1
| 23/05/30 09:15:33 INFO common.Storage: Storage directory /tmp/hadoop-root/dfs/name has been successfully formatted.
|
(6).start-all.sh 启动Hadoop服务
(7).输入jps 查看运行的进程(应有如下6个)
1
2
3
4
5
6
7
| [root@qianfeng01 hadoop]# jps
6433 NameNode
7043 NodeManager
6933 ResourceManager
6550 DataNode
6780 SecondaryNameNode
7375 Jps
|
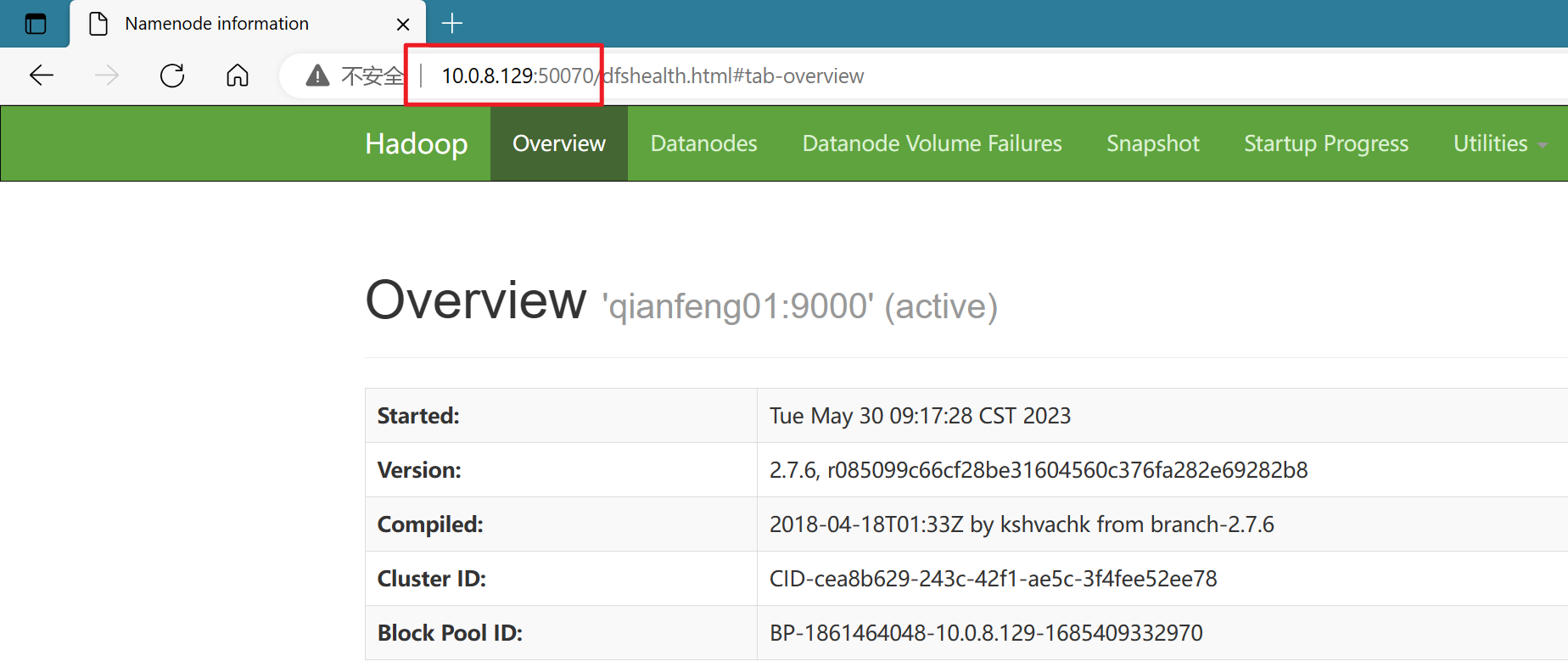
(8).打开浏览器,输入自己的ip:50070 查看HadoopWeb文件系统页面
网页可以正常打开,说明Hadoop伪分布式环境搭建完成~~
1.HDFS常用命令
| 常用命令 |
作用 |
| hadoop fs -put xxx.txt / |
上传xxx文件到hdfs的根目录下 |
| hadoop fs -get /xxx.txt /xxx.txt |
下载xxx文件到Linux本地并重命名 |
| hadoop fs -rm /xxx.txt |
删除hdfs根目录下的文件 |
| hadoop fs -rmdir /xxx |
删除空文件夹 |
| hadoop fs -rmr /xxx |
递归删除文件夹 |
| hadoop fs -ls / |
查看hdfs根目录下的所有文件 |
| hadoop fs -cp /xxx.txt /xxx.txt |
将hdfs根目录下的xxx文件复制并重命名为xxx |
| hadoop fs -mv /xxx.txt /xxx.txt |
将hdfs根目录下的xxx文件重命名为xxx |
| hadoop fs -mv /xxx.txt /xxx/ |
将hdfs根目录下的xxx文件移动到指定文件夹xxx下 |
| hadoop fs -mkdir /xxx |
在hdfs根目录下创建文件夹xxx |
eg.在Linux本地环境创建hello.txt,与HDFS进行文件交互
1
2
| cd /home/data/
vim hello.txt # 创建hello.txt并编辑
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| hadoop fs -put hello.txt / # 上传文件到hdfs的根目录下
mv hello.txt world.txt # 重命名文件夹
hadoop fs -put /home/data/world.txt /a.txt # 上传本地文件到hdfs,并重命名
hadoop fs -mkdir /log # 创建文件夹
hadoop fs -get /a.txt /home/data/ # 从hdfs下载文件到本地
hadoop fs -mv /hello.txt /world.txt # 重命名
hadoop fs -cp /world.txt /hello.txt # 复制文件并重命名
hadoop fs -ls / # 查看hdfs的所有文件
hadoop fs -mv /a.txt /log/ # 移动文件到指定目录下
hadoop fs -rmdir /log # 删除的文件夹必须为空(会报错)
hadoop fs -rm /log/a.txt # 删除文件
hadoop fs -rmdir /log # 删除空文件夹
hadoop fs -mkdir /demo
hadoop fs -mv /hello.txt /demo # 移动(剪切)文件
hadoop fs -mv /world.txt /demo
hadoop fs -rmr /demo # 递归删除文件夹
|
2.HDFS的概述
(1) HDFS:Hadoop Distribute File System (Hadoop分布式文件系统)
(2) HDFS是为了方便使用,仿照Linux系统设计的存储系统
(3) HDFS是典型的主存结构:
NameNode(主节点) 和 DataNode(从节点)
DataNode: 存储实际的数据块
(4) HDFS在存储文件时,会将文件进行物理(Block)切块
(5) HDFS在存储的时候切块之后每个Block默认是128MB
(6) HDFS会自动对数据进行备份,这个备份称之为副本,在完全分布式的场景中的副本数量默认为3
ps:
现代大数据的8大特点(8V)
1.数据量大(Volume) 2.速度(Velocity) 3.种类(Variety) 4.准确性(Veracity)
5.可变性(Variability) 6.波动性(Volatility) 7.可视化(visualization) 8.价值(Value)
3.Block(块存储)
(1).Block是HDFS中数据存储的基本单位,即一个文件在HDFS存储时由一个或多个Block组成
(2).Block的大小默认(Hadoop1.0版本默认是64MB,Hadoop2.0是128MB), 可通过dfs.blocksize属性来设置
(3).若一个文件本身不到128MB,则这个文件是多大则对应的Block就是多大
(4).HDFS会对Block进行编号,即BlockID
(5) 切块的意义
a.能够存储超大文件 b.能够进行快速的备份
4.NameNode
(1).NameNode是HDFS的核心节点(主节点)
(2).NameNode的职责,管理DataNode和记录元数据
(3).元数据包含:
a. 文件的存储路径 b. 文件的大小 c. Block的大小 d. BlockID v. 副本数量
(4). 元数据时存储在内存及磁盘当中的目的
在内存中的目的是查找快,在磁盘中的目的是崩溃恢复
(5).默认情况下DataNode每隔3s发送心跳,给NameNode
5.DataNode
作用:存储Block
DataNode将Block存储在磁盘上,在磁盘上的存储路径是由hadoop.tmp.dir属性来决定的
DataNode会定时向NameNode发送心跳,即RPC远程过程调用
6.SecondaryNameNode
到目前为止HDFS集群只能是NameNode+SecondaryNameNode结构或者是双NameNode结构,
而在实际生存场景中,采用的都是双NameNode结构而舍弃掉SecondaryNameNode
7.垃圾回收机制
HDFS回收站策略默认是不打开的,意味着删除文件这个操作会立即生效并且不能撤销
若要开启回收站功能,需在core-site.xml文件中配置
vim core-site.xml
1
2
3
4
5
6
7
8
9
| <property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
|
从回收站还原的命令:
1
| hadoop fs -mv hdfs://qianfeng01:9000/user/root/.Trash/Current/a.txt /b.txt
|
功能测试
1
2
3
4
5
6
7
8
9
10
| [root@qianfeng01 hadoop]#
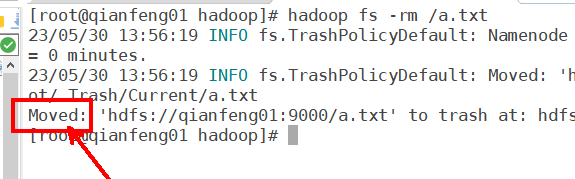
[root@qianfeng01 hadoop]# hadoop fs -rm /a.txt
23/05/30 13:56:50 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 1440 minutes, Emptier interval = 0 minutes.
23/05/30 13:56:50 INFO fs.TrashPolicyDefault: Moved: 'hdfs://qianfeng01:9000/a.txt' to trash at: hdfs://qianfeng01:9000/user/root/.Trash/Current/a.txt
Moved: 'hdfs://qianfeng01:9000/a.txt' to trash at: hdfs://qianfeng01:9000/user/root/.Trash/Current
[root@qianfeng01 hadoop]#
[root@qianfeng01 hadoop]#
[root@qianfeng01 hadoop]#
[root@qianfeng01 hadoop]# hadoop fs -mv hdfs://qianfeng01:9000/user/root/.Trash/Current/a.txt /b.txt # 从垃圾站回收并移动并重命名到根目录下
[root@qianfeng01 hadoop]#
|
测试完成,关闭Hadoop使用命令stop-all.sh
二、搭建完全分布式运行模式
1.虚拟机克隆
从BigData01克隆到BigData02,BigData03
克隆完成后,依次启动三个虚拟机,查看各虚拟机ip是否是依次往后顺延的

没有依次顺延,需要将重复的ip地址更改(BigData02、BigData03的ip地址改为顺延后的)
依次输入vim /etc/sysconfig/network-scripts/ifcfg-ens33来更改网卡配置的ip信息
systemctl restart network 更改好后,重启一下网络
2.Hadoop完全分布式环境配置(类似Day01伪分布式的配置操作)
Day01伪分布式的配置操作
(1).在三个节点上关闭防火墙
1
2
| sudo systemctl stop firewalld # 临时关闭
sudo systemctl disable firewalld # 永久关闭
|
(2).在三个节点上配置主机名称
vim /etc/hostname
将主机名依次指定为qianfeng01,qianfeng02,qianfeng03
(3).配置三个节点的hosts文件
将主机名称和IP地址进行映射
1
2
3
4
5
6
| 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
xx.xx.xx.xx qianfeng01
xx.xx.xx.xx qianfeng02
xx.xx.xx.xx qianfeng03
|
注意,三个节点映射完成后那么三个节点的hostname文件内容将是一样的
(4).对三个节点配置SSH免密互通
三个节点上都需要将生成的公钥拷贝给远程服务器,
1
2
3
4
| ssh-keygen # 生成自己的公钥和秘钥 (依次敲回车即可)
ssh-copy-id root@qianfeng01 # 将生成的公钥拷贝给远程服务器
ssh-copy-id root@qianfeng02
ssh-copy-id root@qianfeng03
|
测试ssh功能,

(5).三个节点重新启动虚拟机让所有的配置生效
三个节点都输入命令,reboot
(6).进入Hadoop安装目录的子目录
cd /home/software/hadoop-2.7.6/etc/hadoop/
a. 编辑hadoop-env.sh文件
vim hadoop-env.sh 一般命令模式下(ESC):set nu
1
2
3
4
5
6
7
8
| 1) 修改第25行JAVA_HOME的路径:
export JAVA_HOME=/home/software/jdk1.8
2) 修改第33行HADOOP_CONF_DIR的路径:
export HADOOP_CONF_DIR=/home/software/hadoop-2.7.6/etc/hadoop
3) 保存退出之后需要让该文件重新生效:
source hadoop-env.sh
|
b. 编辑core-site.xml文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| <configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns</value>
</property>
<porperty>
<name>hadoop.tmp.dir</name>
<value>/home/software/hadoop-2.7.6/tmp</value>
</property>
<property>
<name>ha.zookeeper.orum</name>
<value>qianfeng01:2181,qianfeng02:2181,qianfeng03:2181</value>
</property>
</configuration>
|
c.编辑hdfs-site.xml文件
hadoop01/hadoop02 改为自己的主机名称,同时注意版本号要与自己安装的一致:hadoop-2.7.6
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
| <configuration>
<property>
<name>dfs.nameservices</name>
<value>ns</value>
</property>
<property>
<name>dfs.ha.namenodes.ns</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns.nn1</name>
<value>qianfeng01:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.ns.nn1</name>
<value>qianfeng01:50070</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns.nn2</name>
<value>qianfeng02:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.ns.nn2</name>
<value>qianfeng02:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://qianfeng01:8485;qianfeng02:8485;qianfeng03:8485/ns</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/software/hadoop-2.7.6/tmp/journal</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.ns</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///home/software/hadoop-2.7.6/tmp/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///home/software/hadoop-2.7.6/tmp/hdfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
|
d.编辑yarn-site.xml文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
| <configuration>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>qianfeng01</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>qianfeng03</value>
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>qianfeng01:2181,qianfeng02:2181,qianfeng03:2181</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>ns-yarn</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>qianfeng03</value>
</property>
</configuration>
|
e.编辑map-site.xml文件
先将模板问价复制一份并重命名,cp mapred-site.xml.template mapred-site.xml
再配置map-site.xml文件
1
2
3
4
5
6
7
| <configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
|
f.编辑slaves文件(当前的/home/software/hadoop-2.7.6/etc/hadoop/目录下)
vim slaves
1
2
3
| qianfeng01
qianfeng02
qianfeng03
|
(7)将第一个节点上的Hadoop配置好的整个文件夹拷贝给另外两个节点
1
2
| scp -r hadoop-2.7.6 root@qianfeng02:/home/software/
scp -r hadoop-2.7.6 root@qianfeng03:/home/software/
|