数据分析与可视化 上机实践4(Matplotlib 数据可视化)
一、实践目的
1.了解matplotlib库的基本功能。
2.掌握matplotlib库的使用方法。
二、数据集介绍
食品偏好数据集统计了2019年不同国家人民对不同食物的偏好情况。数据共计288条,各数据字段含义如下表所示。

food.csv 数据集下载
三、实践内容要求
1、绘制正弦曲线,并设置标题、坐标轴名称和坐标轴范围;
2、同一坐标系下绘制多种曲线并通过样式、宽度和颜色加以区分;
3、对食品偏好数据集进行可视化处理。
(1)读取数据集,并显示前5行;
(2)删除无用特征Timestamp和Participant_ID;
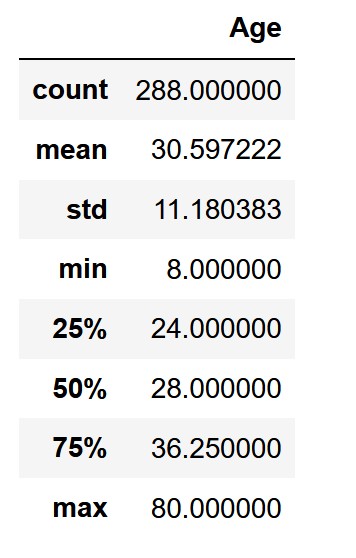
(3)查看数据集的基本情况和统计信息;
(4)绘制不同国家参与者人数柱状图;
(5)利用饼形图分别绘制男性和女性对甜点的偏好;
(6)利用箱体图绘制不同年龄的人对果汁偏爱对比图;
(7)利用散点图绘制不同年龄的人对甜点的偏爱对比图(提示:年龄作为x轴,maybe,yes和no分别用0,1和-1来表示作为y轴,同时用不同颜色的散点表示Traditional Food和Western Food);
(8)根据所绘制的图形,分析人们对不同食物的偏好情况。
四、完成情况
(1)简单绘制曲线
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
%matplotlib inline
data=np.arange(0, np.pi*4, 0.01)
plt.figure(figsize=(4,3),dpi=120)
plt.title('sin(x) 正弦曲线')
plt.xlabel('X')
plt.ylabel('Y')
plt.xlim(0,np.pi*4)
plt.ylim(-1,1)
plt.xticks([0, np.pi/2, np.pi, np.pi*3/2, np.pi*2, np.pi*5/2, np.pi*3, np.pi*7/2, np.pi*4])
plt.yticks([-1,-0.5,0,0.5,1])
plt.plot(data,np.sin(data))
plt.legend(['sin'])
plt.show()
|

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(4,4),dpi=100)
data=np.arange(0,1,0.01)
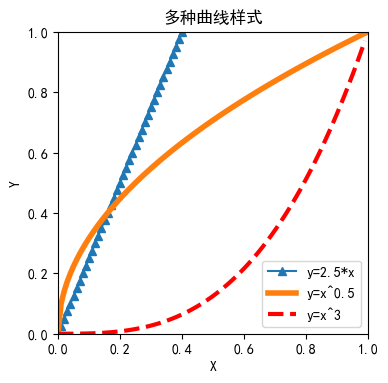
plt.title('多种曲线样式')
plt.xlabel('X')
plt.ylabel('Y')
plt.xlim(0,1)
plt.ylim(0,1)
plt.xticks([0,0.2,0.4,0.6,0.8,1])
plt.yticks([0,0.2,0.4,0.6,0.8,1])
plt.plot(data, 2.5*data, marker='^')
plt.plot(data, data**0.5, linewidth=4)
plt.plot(data, data**3, linewidth=3, linestyle='--', color='red')
plt.legend(['y=2.5*x','y=x^0.5', 'y=x^3'])
plt.show()
|
(2)对食品偏好数据集进行可视化处理
1
2
3
4
5
|
import pandas as pd
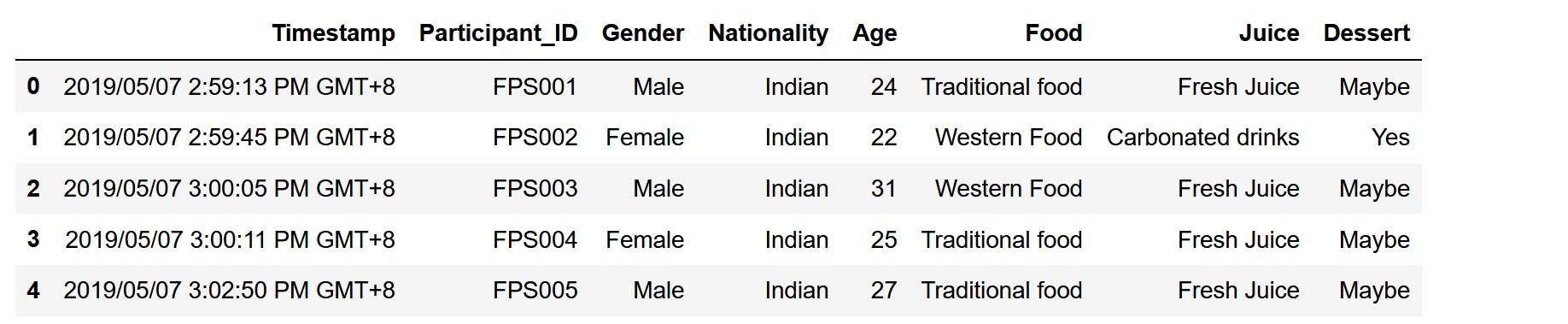
food=pd.read_csv('food.csv')
food.head()
|
1
2
3
4
|
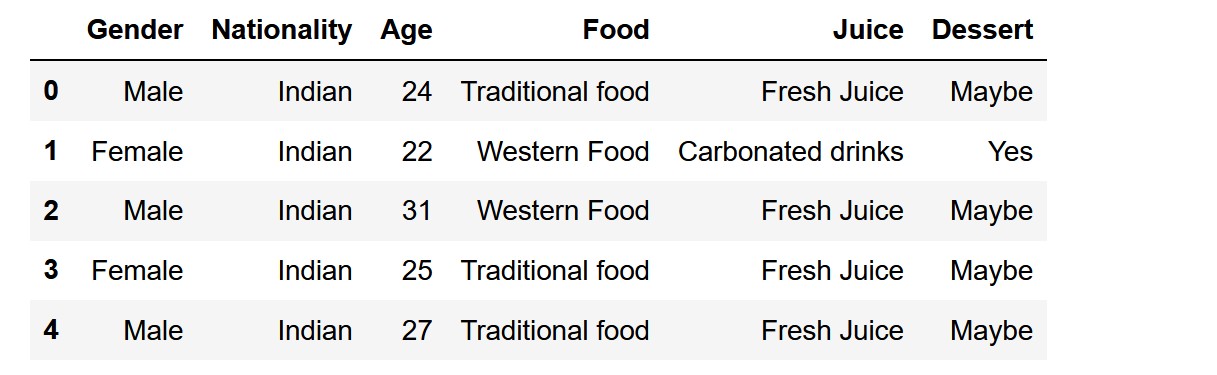
food.drop(['Timestamp','Participant_ID'],axis=1,inplace=True)
food.head()
|
1
2
3
4
5
6
7
8
9
10
11
12
13
| <class 'pandas.core.frame.DataFrame'>
RangeIndex: 288 entries, 0 to 287
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Gender 284 non-null object
1 Nationality 288 non-null object
2 Age 288 non-null int64
3 Food 288 non-null object
4 Juice 288 non-null object
5 Dessert 288 non-null object
dtypes: int64(1), object(5)
memory usage: 13.6+ KB
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = ['SimHei']
plt.figure(figsize=(7,6),dpi=100)
data=food['Nationality'].value_counts()
data.plot(kind='bar',rot=30)
plt.xlabel('国家')
plt.ylabel('人数')
plt.title('不同国家参与者人数柱状图')
plt.bar(range(len( data)),data)
for x,y in zip(range(len(data)),data):
plt.text(x,y,y,ha = 'center',va = 'bottom')
plt.show()
|

1
2
3
|
food.groupby('Dessert')['Gender'].value_counts()
|
1
2
3
4
5
6
7
8
| Dessert Gender
Maybe Female 72
Male 50
No Female 35
Male 17
Yes Female 58
Male 52
Name: Gender, dtype: int64
|
1
| food['Gender'].value_counts()
|
1
2
3
| Female 165
Male 119
Name: Gender, dtype: int64
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| plt.figure(figsize=(10,8),dpi=90)
plt.subplot(1,2,1)
labels=['Maybe','No','Yes']
x=[72/165, 35/165, 58/165]
explode=(0.01, 0.01, 0.01)
plt.pie(x, labels=labels, explode=explode, startangle=60, autopct='%1.1f %%')
plt.title('男性对甜点的偏好')
plt.legend()
plt.subplot(1,2,2)
labels=['Maybe','No','Yes']
x=[50/119, 17/119, 52/119]
explode=(0.01, 0.01, 0.01)
plt.pie(x, labels=labels, explode=explode, startangle=60, autopct='%1.1f %%')
plt.title('女性对甜点的偏好')
plt.legend()
plt.show()
|

1
2
3
|
food.groupby('Juice')['Age'].value_counts()
|
1
2
3
4
5
6
7
8
9
10
11
12
13
| Juice Age
Carbonated drinks 21 5
23 4
25 3
22 2
24 2
..
Fresh Juice 60 1
63 1
65 1
67 1
74 1
Name: Age, Length: 66, dtype: int64
|
1
| food['Juice'].value_counts()
|
1
2
3
| Fresh Juice 256
Carbonated drinks 32
Name: Juice, dtype: int64
|
1
2
3
4
5
6
7
8
9
10
11
12
13
| import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(figsize=(6,6),dpi=90)
sns.boxplot(x=food['Age'], y=food['Juice'], data=food, orient='h')
plt.xlabel('Age')
plt.ylabel('Juice')
plt.show()
|

1
2
3
4
|
df=food.groupby('Dessert')['Age'].value_counts()
|
1
2
3
| plt.figure(figsize=(8,4),dpi=90)
plt.scatter(food['Age'], food['Dessert'], color='green')
|

1
2
3
4
5
6
7
8
9
10
11
12
13
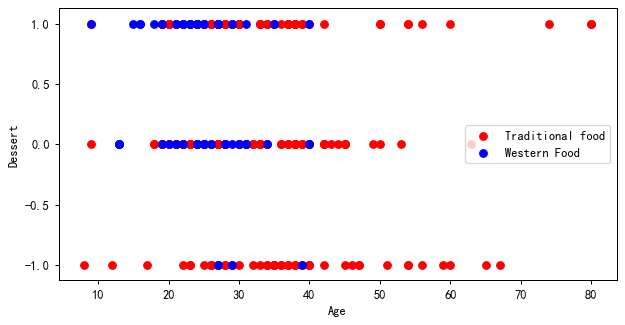
| plt.figure(figsize=(8,4),dpi=90)
traditional_likes = food[food['Food'] == 'Traditional food']['Dessert'].replace({'Yes': 1, 'Maybe': 0, 'No': -1})
western_likes = food[food['Food'] == 'Western Food']['Dessert'].replace({'Yes': 1, 'Maybe': 0, 'No': -1})
age = food['Age']
plt.scatter(age[food['Food'] == 'Traditional food'], traditional_likes, color='red', label='Traditional food')
plt.scatter(age[food['Food'] == 'Western Food'], western_likes, color='blue', label='Western Food')
plt.xlabel('Age')
plt.ylabel('Dessert')
plt.legend()
plt.show()
|
1
2
3
4
| #(8)根据所绘制的图形,分析人们对不同食物的偏好情况。
# 在该图中,红色表示传统美食的偏好程度,蓝色表示西方美食的偏好程度。可以得出结论,在所有年龄段中人们似乎更喜欢传统美食。
# 其中在年龄20到40之间的人群对传统美食的偏爱程度较高,年龄在15到30之间的人群对西方美食偏爱程度较高。
|
五、参考资料
food.csv 数据集下载
(5), (6), (7)中的可视化处理参考了chatgpt提供的解题思路





