数据分析与可视化 实践基础练习五(Pandas)
数据分析与可视化 实践基础练习五 (Pandas)
一、本节需要掌握的Pandas相关函数或属性
Pandas数据运算
Pandas常用的汇总与统计性方法
数据分组df.groupby( )
参数by:可以是函数,字典,Series; axis=0是按列,1是按行
数据聚合agg()、apply()、transform()
agg(): 可对分组后的数据进行一系列的操作包含求和求最值,均值等
apply(): 可自定义面向分组的聚合函数(Series对象是对每个元素处理,DataFrame对象是对一行或一列处理,groupby对象是对一个分组进行处理)
transfrom(): 不对数据进行聚合输出,而只是对每一行记录提供了相应的聚合结果(输出结果有冗余)
二、实训案例
1.行星数据集记录了2014年之前发现的行星的信息,数据中主要特征有:

2. 结合数据集完成以下操作。
(1)读取planets.csv文件;
(2)查看数据前5行;
(3)查看数据基本情况;
(4)按method特征对数据进行分组,并将新数据记为grouped;
(5)将数据按发现年份在2000年前和2000年后进行分组;
(6)求2000年前和2000年后的分组均值;
(7)查看不同方法发现的行星与地球距离的中位数;
(8)按发现行星的方法和发现的年代进行分组,并统计相应分组下发现的行星的总数;
(9)计算不同方法发现的行星在各特征上的极差;
(10)分别计算各种方法发现的行星的距离的均值和发现的数量之和。
三、题解
1 | #(1)读取planets.csv文件,导入行星数据表到DataFrame中; |
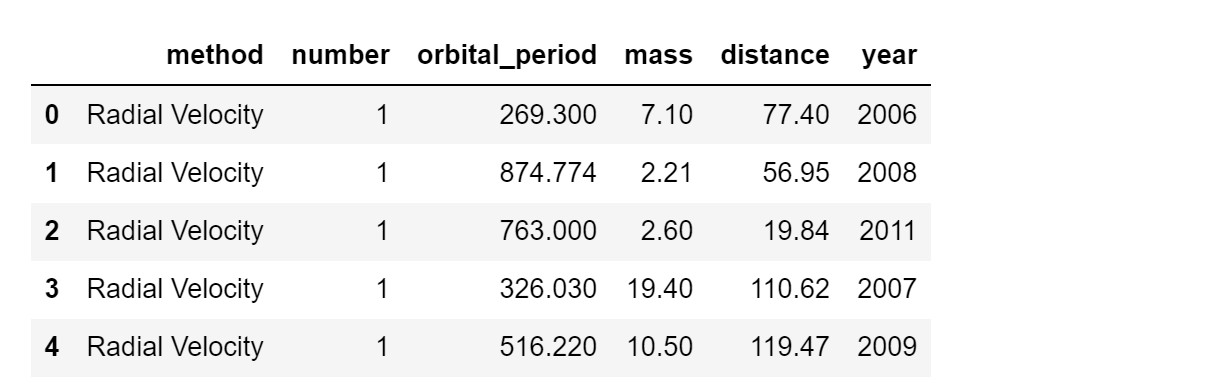
1 | #(3)查看数据基本情况; |
1 | <class 'pandas.core.frame.DataFrame'> |
1 | #(4)按method特征对数据进行分组,并将新数据记为grouped; |
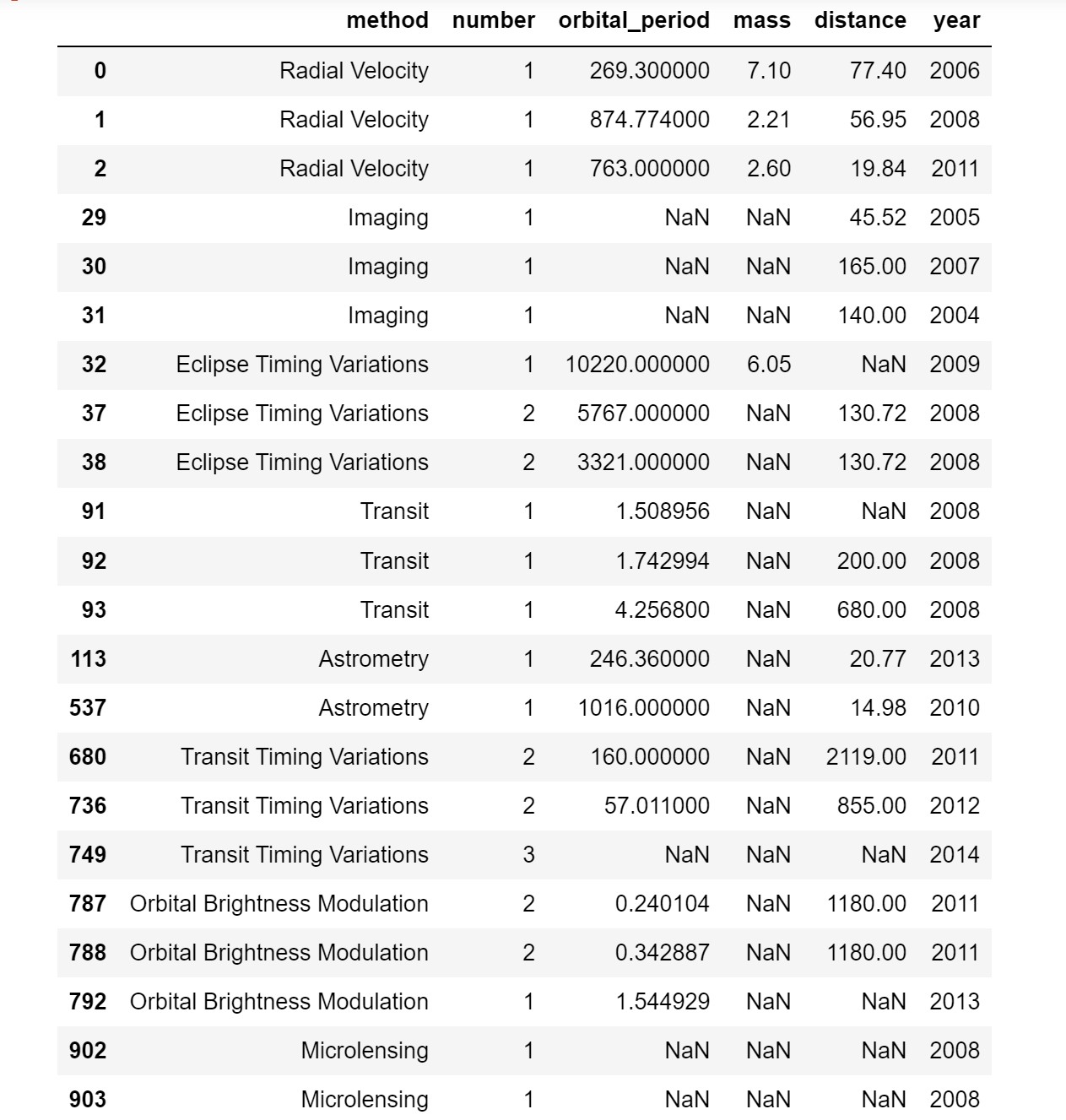
1 | #(5)将数据按发现年份在2000年前和2000年后进行分组; |

1 | #(6)求2000年前和2000年后的分组均值; |

1 | #(7)查看不同方法发现的行星与地球距离的中位数; |
1 | method |
1 | #(8)按发现行星的方法和发现的年代进行分组,并统计相应分组下发现的行星的总数; |
1 | method year |
1 | #(9)计算不同方法发现的行星在各特征上的极差; |

1 | #(10)分别计算各种方法发现的行星的距离的均值和发现的数量之和。 |

四、参考资料
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 AriesfunのBlog!
相关推荐


评论


