数据分析与可视化 实践基础练习四(Pandas)
数据分析与可视化 实践基础练习四 (Pandas)
一、本节需掌握的Pandas相关函数或属性
1 | 1. Series和DataFrame数据类型的创建 |
二、实训案例
1. Pokemon宠物小精灵数据初步探索。
案例中使用宠物小精灵的相关数据进行分析,其中各列的列名意义为:
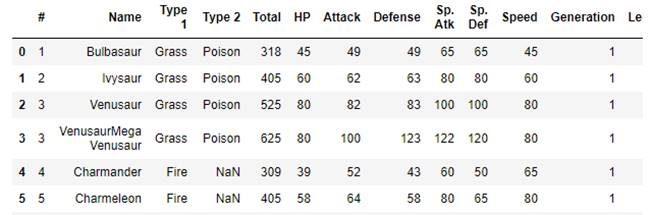
· name:宠物小精灵的名称
· Type 1:宠物小精灵的第一类型 Type 2:宠物小精灵的第二类型
· Total:综合能力(生命点数、攻击强度、防御强度、特殊攻击强度、特殊防御强度和速度的总和)
· HP:生命点数
· Attack:攻击强度 Defense:防御强度
· Sp.Atk:特殊攻击强度 Sp.Def:特殊防御强度
· Speed:速度 Generation:世代数
· Lengendary:True表示为传奇小精灵,False表示非传奇小精灵
2. 结合数据集完成以下相关操作。
(1)读取Pokemon.csv文件;
(2)展示数据前10行;
(3)删除名为“#”的列;
(4)将各列名改为中文, 参数inplace设置替换原数据;
(5)分别查看数据表的行、列索引;
(6)查看第一类型的唯一值;
(7)查看行标签为2、4小精灵的名称和综合能力;
(8)查看行标签为5到10小精灵的名称和综合能力;
(9)通过切片方式查看前6个小精灵的数据;
(10)查看攻击强度大于160的小精灵的所有数据;
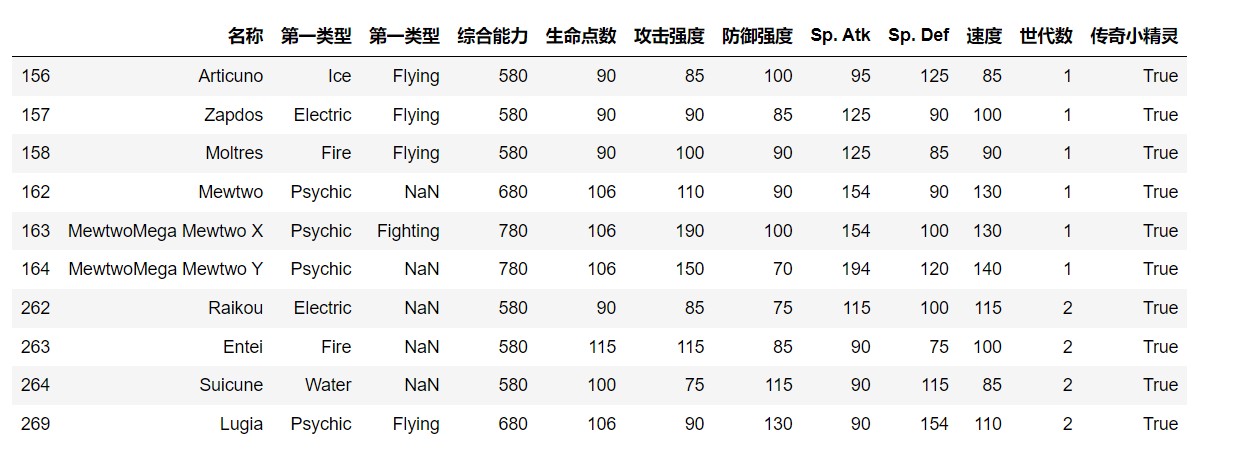
(11)查看传奇小精灵的数据,只展示前十行数据;
(12)创建新列“能力600”,插入到综合能力一列的后面,该列显示综合能力大于等于600的为True,小于600为False;
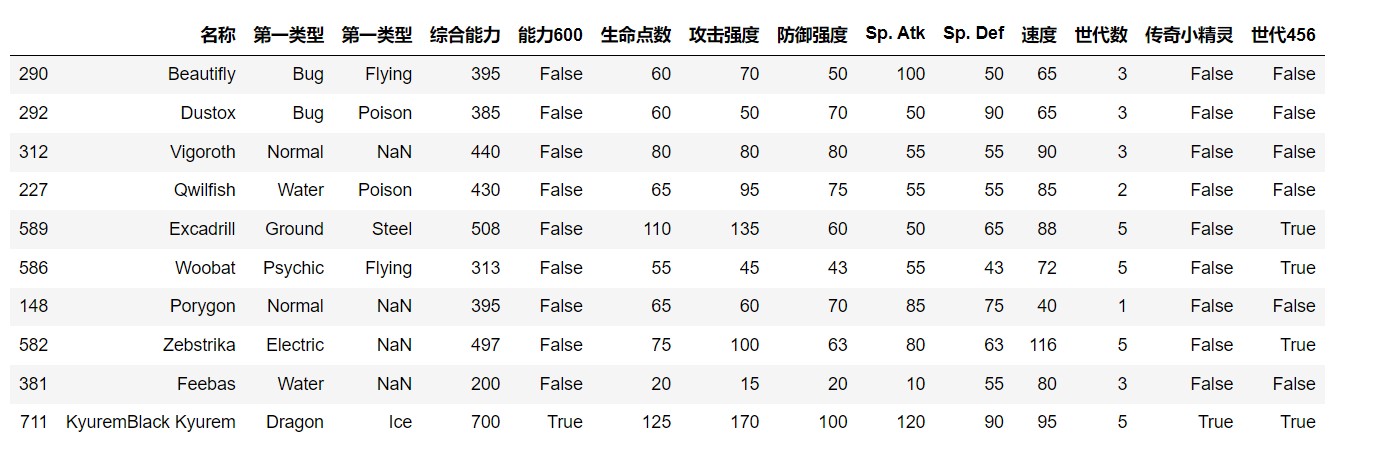
(13)创建新列“世代456”,插入到最后一列,该列显示世代数为4、5和6的小精灵为True, 其他为False,随机选取10行数据进行展示。
三、题解
1 | # (1)读取Pokemon.csv文件; |
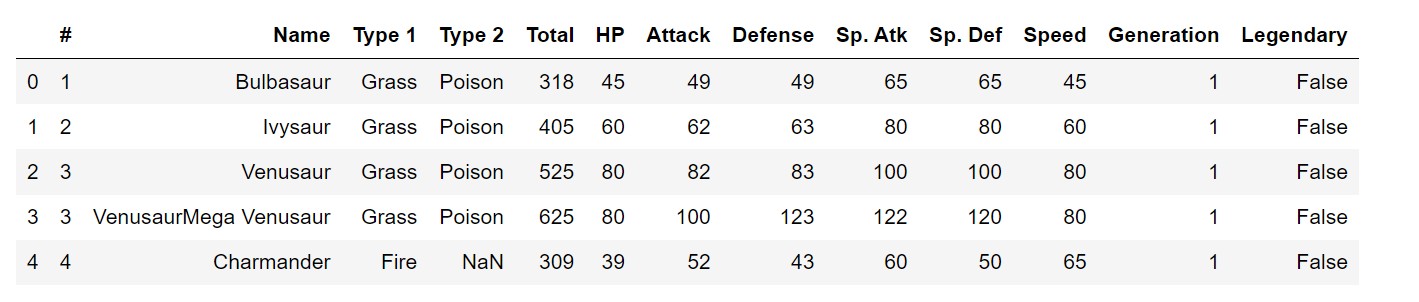
1 | # (2)展示数据前10行; |

1 | # (3)删除名为“#”的列; |

1 | # (4)将各列名改为中文, 参数inplace设置替换原数据; |
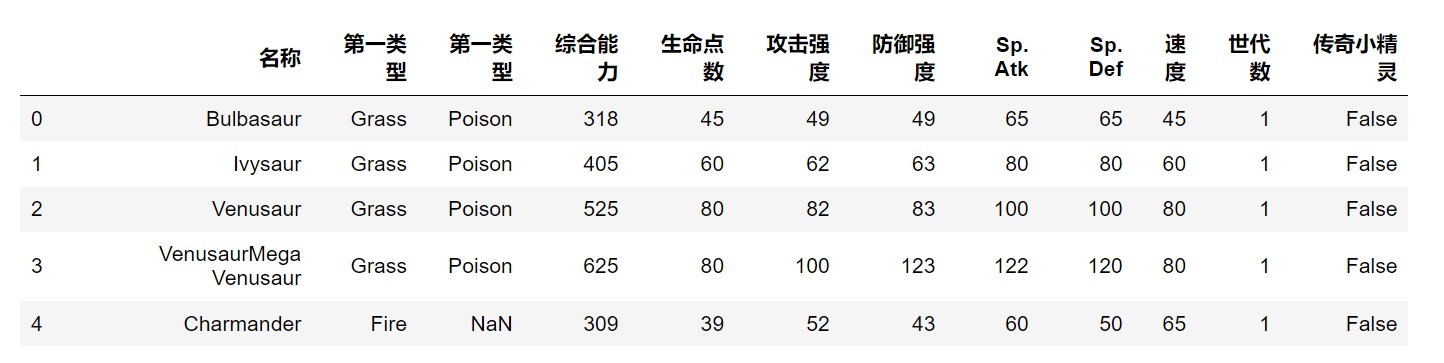
1 | # (5)分别查看数据表的行、列索引; |
1 | ['名称', |
1 | # (6)查看第一类型的唯一值; |
1 | 第一类型 18 |
1 | # (7)查看行标签为2、4小精灵的名称和综合能力; |
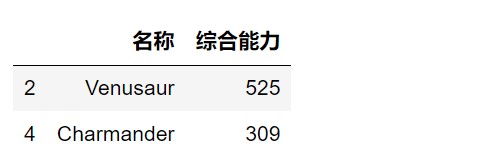
1 | # (8)查看行标签为5到10小精灵的名称和综合能力; |

1 | # (9)通过切片方式查看前6个小精灵的数据; |

1 | # (10)查看攻击强度大于160的小精灵的所有数据; |

1 | # (11)查看传奇小精灵的数据,只展示前十行数据; |
1 | # (12)创建新列“能力600”,插入到综合能力一列的后面,该列显示综合能力大于等于600的为True,小于600为False; |

1 | # (13)创建新列“世代456”,插入到最后一列,该列显示世代数为4、5和6的小精灵为True, 其他为False,随机选取10行数据进行展示。 |
四、参考资料
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 AriesfunのBlog!
相关推荐


评论


