数据分析与可视化 上机实践2(Pandas 统计分析)
数据分析与可视化 上机实践2(Pandas 统计分析)
一、实践目的
1.了解 Pandas 库的基本功能。
2.掌握 Pandas 库的使用方法。
二、数据集介绍
本实验使用酒品消耗量数据集,其记录了全球 193 个国家某年的各类酒品消
耗数据,主要数据集变量如下:

三、实践内容要求
- 数据预处理
(1)导入 excel 表格中的数据到 DataFrame 中;
(2)查看数据的前 5 行和后 8 行。
- 数据操作
(1)查看数据中各变量类型;
(2)将啤酒销量改成 object 类型;
(3)将列名的英文改为中文格式;
(4)初步查看数据类型和大小;
(5)查看数据数值统计情况;
(6)查看索引值;
(7)将索引值修改为所在的大洲;
(8)查看缺失值情况;
(9)采用恰当的方法对缺失值进行填充。
- 饮酒情况对比
(1)查找啤酒、烈酒和红酒的消耗量都高于相应酒种消耗量 75%分位数的
国家;
(2)统计(1)中各大洲国家的个数;
(3)统计各个大洲各类酒的消耗总量;
(4)计算各类酒占各大洲总消耗量的比重。
4.通过饮酒情况对比,对各大洲的饮酒习惯进行分析。
四、完成情况
1 | # 1. 数据预处理 |

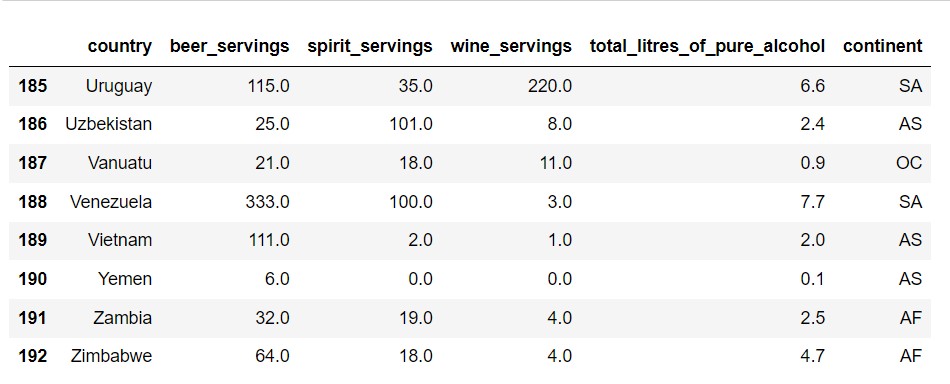
1 | df.tail(8) # 查看数据的后8行 |
1 | # 2. 数据操作 |
country object
beer_servings float64
spirit_servings float64
wine_servings float64
total_litres_of_pure_alcohol float64
continent object
dtype: object
1 | #(2)将啤酒消耗量改成 object 类型; |
country object
beer_servings object
spirit_servings float64
wine_servings float64
total_litres_of_pure_alcohol float64
continent object
dtype: object
1 | #(3)将列名的英文改为中文格式; |

1 | #(4)初步查看数据类型和大小; |
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 193 entries, 0 to 192
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 国家 193 non-null object
1 啤酒消耗量 190 non-null object
2 烈酒消耗量 190 non-null float64
3 红酒消耗量 190 non-null float64
4 总酒精消耗量 193 non-null float64
5 所在大洲 170 non-null object
dtypes: float64(3), object(3)
memory usage: 9.2+ KB
1 | #(5)查看数据数值统计情况; |

1 | #(6)查看索引值; |
['国家', '啤酒消耗量', '烈酒消耗量', '红酒消耗量', '总酒精消耗量', '所在大洲']
1 | #(7)将索引值修改为所在的大洲; |

1 | #(8)查看缺失值情况; |
国家 0
啤酒消耗量 3
烈酒消耗量 3
红酒消耗量 3
总酒精消耗量 0
所在大洲 23
dtype: int64
1 | #(9)采用恰当的方法对缺失值进行填充。 |
国家 0
啤酒消耗量 0
烈酒消耗量 0
红酒消耗量 0
总酒精消耗量 0
所在大洲 23
dtype: int64
1 | # 3. 饮酒情况对比 |
3 Andorra
25 Bulgaria
44 Cyprus
45 Czech Republic
60 Finland
75 Hungary
93 Latvia
99 Luxembourg
141 Russian Federation
151 Serbia
155 Slovakia
160 Spain
184 USA
Name: 国家, dtype: object
1 | #(2)统计(1)中各大洲国家的个数; |
EU 11
AS 1
Name: 所在大洲, dtype: int64
1 | #(3)统计各个大洲各类酒的消耗总量; |
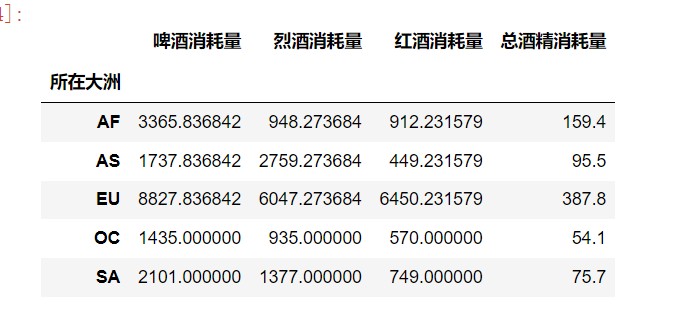
1 | #(4)计算各类酒占各大洲总消耗量的比重。 |

1 | # 4.通过饮酒情况对比,对各大洲的饮酒习惯进行分析。 |
所在大洲
AF 159.4
AS 95.5
EU 387.8
OC 54.1
SA 75.7
Name: 总酒精消耗量, dtype: float64
五、参考资料
Pandas中计算分位数的方法describe、quantile
遇到问题及解决方案
Python报错解决:TypeError: Cannot interpret ‘<attribute ‘dtype‘ of ‘numpy.generic‘objects>‘as a data type
成功更新pandas后,问题得到解决

本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 AriesfunのBlog!
相关推荐


评论


